Codice Genetico
Il codice genetico è l’insieme di regole molecolari attraverso cui l’informazione contenuta nelle sequenze nucleotidiche (DNA e RNA) viene tradotta in sequenze amminoacidiche delle proteine.
L’informazione viene decodificata a gruppi di tre nucleotidi contigui chiamati codoni (o triplette).
Logica delle Triplette ed Esperimenti di Decifrazione
La scelta di un codice a triplette risponde a una necessità matematica di codifica di diversi amminoacidi a partire da basi azotate distinte:
- 1 base per amminoacido: combinazioni possibili (insufficienti).
- 2 basi per amminoacido: combinazioni possibili (insufficienti).
- 3 basi per amminoacido (triplette): combinazioni possibili (sufficienti per coprire i amminoacidi, lasciando combinazioni in eccedenza).

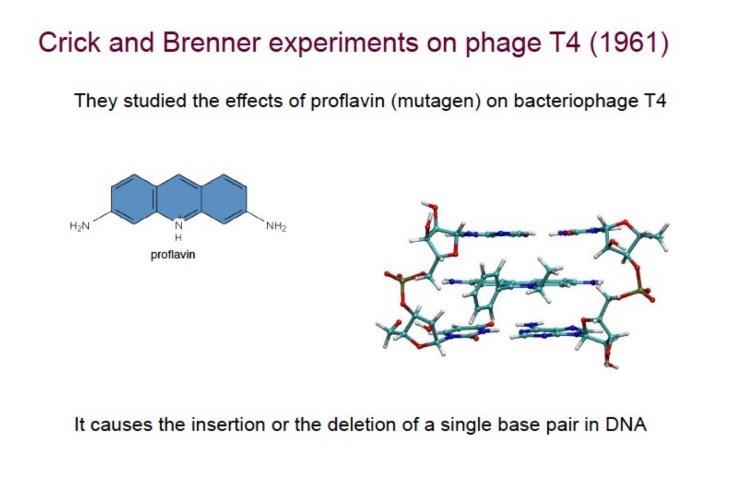
Esperimento di Crick e Brenner con il Fago T4
La natura a triplette del codice genetico è stata dimostrata sperimentalmente nel 1961 da Francis Crick e Sydney Brenner studiando mutazioni nel locus rII del batteriofago T4 indotte da mutageni frameshift (come la proflavina, un intercalante che provoca inserzione/delezione di singole basi):
📌 Come fu letto il risultato: nel 1961 non si sequenziava né si analizzavano le proteine. Crick e Brenner usavano un saggio fenotipico: il fago rII funzionante forma un certo tipo di placche su E. coli, il mutante no. Combinando le mutazioni frameshift e osservando se il fenotipo si ripristinava (placche normali = proteina di nuovo funzionante) deducevano se la cornice fosse tornata in fase.
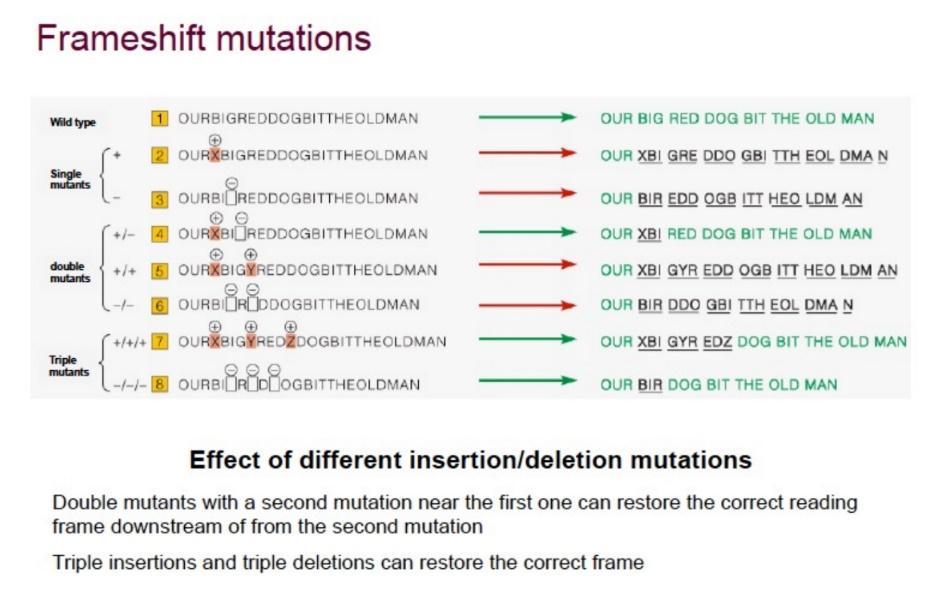
- Singola Inserzione o Delezione (+1 / -1): Sposta completamente la cornice di lettura (reading frame) da quel punto in poi, alterando l’intera sequenza amminoacidica a valle e producendo una proteina non funzionale (out of frame).
- Doppia Inserzione o Delezione (+2 / -2): Mantiene la cornice di lettura alterata (sfasata di 2 ≡ sfasata di 1 nell’altro verso: non torna mai in fase con l’originale), quindi a valle la proteina resta sbagliata.
- Tripla Inserzione o Delezione (+3 / -3): Ripristina la cornice di lettura originale (in frame) a valle del sito mutato, inserendo o eliminando semplicemente un amminoacido. Questa è stata la prova definitiva che il codice viene letto in unità discrete di tre nucleotidi.
Proprietà del Codice Genetico
Il codice genetico presenta proprietà peculiari selezionate evolutivamente per ottimizzare la tolleranza alle mutazioni:

- Degenerato (o Ridondante): Più codoni diversi possono specificare lo stesso amminoacido. Delle 64 triplette totali:
- 61 codoni sono codificanti (incluso il codone d’inizio AUG per la metionina).
- 3 codoni non codificano per alcun amminoacido e fungono da segnali di terminazione della traduzione (UAA, UAG, UGA, detti codoni di stop).
- Non Ambiguo: Ogni singolo codone ha un unico e preciso significato (un codone codifica per un solo amminoacido, non può codificare per amminoacidi diversi in momenti differenti).
- Non Sovrapposto: Ciascun nucleotide fa parte di un solo codone; la lettura avviene sequenzialmente base dopo base senza condivisione di nucleotidi tra codoni adiacenti.
- Senza Punteggiatura: La lettura avviene in modo continuo dall’inizio alla fine, senza nucleotidi “spaziatori” tra una tripletta e la successiva.
- Universale: È identico in quasi tutti gli organismi viventi. Un RNA umano introdotto in un batterio come E. coli viene tradotto nella stessa identica proteina, dimostrando l’origine evolutiva comune di tutti i viventi.
Struttura e Regole di Lettura
Il codice genetico viene comunemente rappresentato sotto forma di tabella.
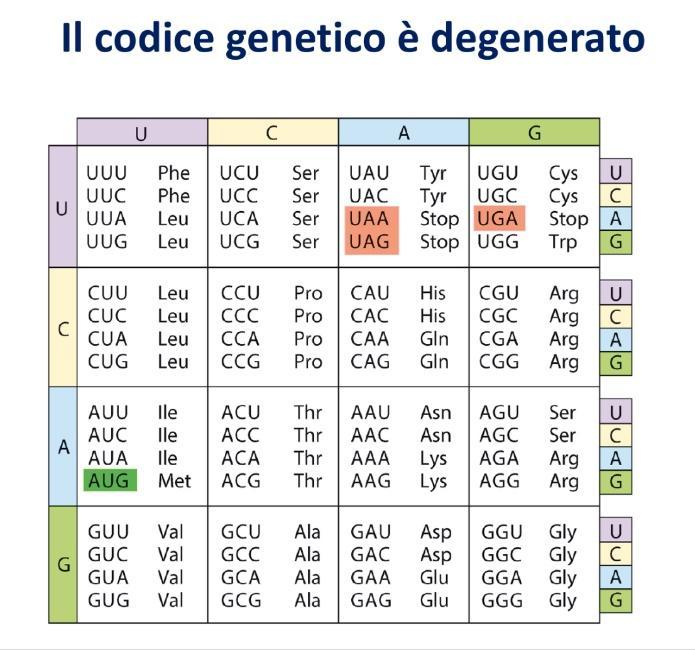

- Regola della Terza Base: Quando un amminoacido è codificato da più triplette, la variazione riguarda quasi sempre il terzo nucleotide del codone, mentre il primo e il secondo rimangono costanti. Il nucleotide centrale (secondo) non cambia mai per lo stesso amminoacido. Questa disposizione minimizza l’effetto delle mutazioni puntiformi spontanee.
L’Accoppiamento Oscillante (Wobble Hypothesis)
La degenerazione del codice si riflette anche a livello dei tRNA. Non esistono 61 tRNA differenti (uno per ciascun codone codificante), ma circa 40 (la letteratura indica circa 40-45). Questo è spiegato dall’accoppiamento oscillante teorizzato da Crick:
- L’appaiamento tra la terza base del codone (sull’mRNA) e la prima base dell’anticodone (sul tRNA) è meno rigido e non segue strettamente le regole standard di Watson-Crick. Il nucleotide in terza posizione si comporta essenzialmente come un “jolly”.
- Ruolo dell’Inosina: Questa vacillazione è dovuta in larga parte alla presenza di inosina (una base azotata modificata prodotta per editing del tRNA) in prima posizione sull’anticodone, che permette l’appaiamento flessibile con diversi nucleotidi dell’mRNA. (Nota: i dettagli degli appaiamenti specifici non sono richiesti).
- Un singolo tRNA può quindi appaiarsi e leggere più codoni sinonimi che differiscono solo per il terzo nucleotide.
Open Reading Frame (ORF)
Un Open Reading Frame (cornice di lettura aperta) è una porzione di sequenza nucleotidica compresa tra un codone d’inizio (AUG) e un codone di stop (UAA, UAG o UGA) che possiede una lunghezza sufficiente a codificare per una proteina funzionale.
Per qualunque sequenza di DNA a doppio filamento esistono 6 possibili cornici di lettura:
- 3 cornici sul filamento stampo (avviando la lettura dal 1°, 2° o 3° nucleotide).
- 3 cornici sul filamento complementare letto in direzione opposta.
La ricerca delle ORF è il metodo bioinformatico primario per identificare i geni codificanti all’interno di una sequenza genomica.
(Sezione espansa con: sbobina 25)
🔗 Collegamenti
- Sintesi Proteica — 📋 fa parte di
- tRNA — 🔗 stesso meccanismo / stessa via
- RNA Messaggero — 📋 fa parte di
- Mutazioni — ⬆️ causa
- Proflavina — ⬇️ conseguenza
- Inosina — 🔗 stesso meccanismo / stessa via